쇼핑몰 사이트에서 API를 이용해서 이것저것 정보를 가져올 때, 이 쇼핑몰에서는 당연하게도 제가 요청한 내용과 저를 증명할 수 있는 방법을 요구하는데요. 이 쇼핑몰에서는 SHA-256 알고리즘(SHA는 Secure Hash Algorithm의 줄임말)을 이용해서 암호화를 하길래 NodeJS 모듈인 Crypto를 이용해서 Hash값과 HMAC값을 만들었습니다.
여기서 잠깐, Hash는 뭐고 HMAC이 무엇인지 간단하게 설명하고 갈게요.
※ Hash(해시)
단방향 암호화 기법 중 하나인 해쉬 알고리즘을 이용해서 일정한 길이의 암호화된 문자열을 생성하는 일을 Hashing이라고 하고, 그 Hashing 이후의 값을 Hash 값, Hash 값을 만들어내는 함수를 Hash 함수라고 합니다. Hash라고 하면 대략 Hash 알고리즘을 이용한 암호화라고 이해하면 될거 같아요.
※ HMAC(Hash based Message Authentication Code)
HMAC에서 MAC는 메세지를 주는 사람과 받는 사람 사이에 그 메세지가 변형되지는 않았는지 확인하는 방법(변조 여부)으로 앞에 "H"가 붙으면 Hash 알고리즘을 이용한다는 뜻입니다.
Hash 함수 안에는 여러 가지 알고리즘이 있는데 요즘은 제가 쓰고 싶은 API는 SHA-256 방식의 알고리즘을 이용하라고 하니 그대로 적용해보겠습니다.
▷ Hash 값
1. 모듈을 import 해줍니다.
import crypto from "crypto"
2. 암호화 해주고 싶은 base_str을 다음처럼 암호화합니다.
const base_str = "this_is_base_string"
const result = crypto.createHash('sha256').update(base_str).digest('hex')
여기서 결과값은 result에 담기게 됩니다.
내용을 대략적으로 설명해보자면 다음과 같습니다.
crypto 모듈을 이용해서 SHA-256 알고리즘('sha256')으로 해시 함수인 ceateHash를 통해 암호화를 한다. 암호화할 문자열은 base_str이고, 결과값을 hex 방식으로 표현한다.
여기서 digest에 hex라는 말은 표현 방식인데, 가능한 표현방식으로는 'binary', 'hex', 'base64'가 있습니다. 'binary'는 2진수, 'hex'는 16진수, 'base64'는 64진수를 나타는데, 제가 쓸 API는 'hex' 방식을 요구하니까 'hex'를 사용합니다.
이번 포스팅에는 저번에 이어서 한번 더 크롤링(crawling or scrapping)을 해볼까 합니다.
이번 포스팅에서는 cheerio라는 라이브러리를 다뤘었는데요. 이번에는 웹에 들어가서 여러 가지 "javascript의 일"을 할 수 있는 라이브러리를 다뤄보려고 합니다. 바로 "꼭두각시"라는 뜻을 가지고 있는 듯한 "Poppeteer"입니다.
cheerio와 다른 점이라면 웹사이트에 로그인을 한다던가, 웹사이트 스크린샷을 찍어서 파일로 저장한다던가, PDF로 만들어서 저장한다던가 하는 일들을 할 수 있습니다.
이번에 제가 보여드릴 예제는 "상품 긁어오기"입니다. 상품을 긁어오는데 cheerio면 충분할 줄 알았는데 복병이 있었습니다. 바로 네이버..
네이버는 상품의 옵션을 보여줄 때 옵션 버튼을 클릭하기 전까지는 옵션의 엘리먼트들을 "hidden"처리를 해놓기 때문에 cheerio로는 긁어오는 것이 불가능합니다.
삼다수를 제주도에서 시키면 4천원 배송비가 더 드는 현실
요로코롬 눌러줘야 옵션 창이 뜹니다. 그래서 제가 이야기했던 "자바스크립트의 일"인 버튼을 클릭하는 일을 할 수 있는 라이브러리를 찾던 중에 Puppteer를 발견한 것이었습니다.
이 라이브러리는 chromium의 렌더링 엔진을 사용해서 headless browser 제어를 도와줍니다.
말이 어렵군요.. 제가 이해하는 방식으로 설명해보겠습니다.(저처럼 이해해도 사용하는데 문제가 "아직은" 없었으니까요.)
일반적으로 우리가 사용하는 크롬처럼 GUI방식의 웹브라우저를 CLI(Command Line Interface) 방식으로 제어한다고 생각하면 쉬울 것 같습니다. 맥이면 터미널, 윈도우면 cmd창으로 브라우저를 제어한다는 의미입니다. 크롬 창을 띄우지 않았는데 크롬창을 띄운 것처럼 실행하고 반응하고 원하는 작업을 할 수 있는 것입니다.
async function scrapeWeb {
// headless browser start
const browser = await puppeteer.launch()
// open new page
const page = await browser.newPage()
// connect web link
await page.goto('http://example.com')
// wait page
await page.waitForNavigation({timeout: 10000})
// click event
await page.click("a.a_class")
// wait option popup
await page.waitForSelector('ul.li_class', {timeout: 10000})
// scrape web data
data = await page.evaluate( () => {
// do something you want
title = document.querySelector("._3oDjSvLwq9").textContent
return {
title: title
}
})
// close browser
await browser.close()
}
poppeteer.launch()는 기본값으로 headless로 실행이 됩니다.
page.waitForNavigation({timeout:10000})은 페이지가 완전히 로딩되기를 기다립니다. 이 메소드의 실행 완료를 기다리지 않고 클릭 메소드를 실행해도 ul 엘리먼트가 감지 되지 않아서 꼭 필요합니다. timeout은 기본값이 30초인데, 페이지의 완전한 로딩을 30초 동안 기다려준다는 뜻입니다. 제가 성격이 느긋하다지만 오류가 생겨도 30초는 못기다리겠더라구요. 오류가 생겼으면 빨리 뱉으라는 심정으로 10초로 줄였습니다.(열리더라도 10초 넘게 기다려야되면 그것도 오류아닌가요 여러분?)
페이지의 로딩을 기다리고 클릭도 하고 ul 엘리먼트가 생기는 것을 확인한 후에 page.evaluate() 메소드를 이용해서 하고 싶은 작업을 맘껏 하시면 됩니다.
그리고 잊지 말고 browser.close() 하면 끝.
4. 끝
끝입니다.
5. 번외 & 팁
5-1. page.evaluate에 argument(인자)를 전달하고 싶을 때
page.evaluate( (name) => {
const data = `${name}`
return data
}, name)
5-2. page.evauluate에 인자를 여러 개 전달하고 싶을 때
5-2-1. 객체 법
page.evaluate( ({name, age, gender}) => {
const data = `${name}${age}${gender}`
return data
}, {name, age, gender})
5-2-1. 직렬 법
page.evaluate( (name, age, gender) => {
const data = `${name}${age}${gender}`
return data
}, name, age, gender)
원하시는 방법대로 인자를 전달하세요.
5-3. page.evaluate() 안에서 console.log는 에러를 뱉어냅니다.
console.log를 하면 에러( Evaluation failed: ReferenceError: _ac2 is not defined )를 뱉어냅니다. _ac2는 랜덤하게 바뀌는 문자열입니다. 정확한 원인을 찾지 못해서, 또는 찾은걸 해봤는데 안 돼서, 또는 찾았는데 이해가 안돼서 그냥 저는 값을 계속 return 시켜보면서 확인했습니다.
=>2021.3.13 추가
역시 모르면 공부하면 알게되는데 귀찮아서 미루고 있다가 지금 알게되었습니다. evaluate는 저쪽 크롤링을 시전하고 있는 puppeteer쪽 크롬창에 명령을 한번에 전달하는 메소드입니다. 그래서 그 안에 console.log를 하면 저쪽 크롬창에 뜨게 되는 것이죠. puppeteer를 launch할 때 옵션으로 {headless: false}옵션을 주면 창이 하나 뜨면서 확인이 가능합니다. 물론 나중에는 다시 꺼놔야겠지요!
저는 뭔가를 빠르게 구현해보고 싶을 때 PHP framework인 라라벨을 주로 사용하는데 웹 크롤링을 하기 위해 빠르게 비동기적으로 처리가 가능한 nodeJS를 선택했습니다. PHP는 언어의 특성상 크롤링을 하는데 적합하지 않다고 판단했습니다. 하나의 명령을 처리하고 그 명령을 완료하기 전에 다음으로 넘어가지 않아 많은 명령을 동시에 처리하지 못하는 한계를 가지고 있기 때문입니다. 물론, 그것을 보완하는 방법들도 있기는 하지만 그냥 nodeJS로 구현하면 쉬워져요.. 심지어 빠릅니다.
슈로록
쿠팡에서 아이템의 수량을 주기적으로 파악해야 할 일이 생겨서 웹사이트를 들락날락하던 중에 클릭이 귀찮아져서 그냥 하나 만들어 봤습니다.
자세히 보면 1번 행부터 순차적으로 진행되는 것이아니라 순서 없이 요청이 완료되는 순서대로 값이 보입니다. 이것이 nodeJS의 힘. 그럼 바로 하나씩 진행해 보겠습니다.
1. vue cli를 이용하여 프로젝트 만들기
여기서 두가지 방법으로 나누어집니다.
첫 번째는, 폴더를 두 개 만들어서(frontend, backend) frontend폴더에 vue-cli를 이용해서 프로젝트를 만들고, backend 폴더에 nodeJS, express 프로젝트를 만들어서 api 통신하게 만드는 방법!
두 번째는 vue-cli로 프로젝트를 만들어서 express plugin을 이용하는 방법!
첫 번째 방법은 다른 분들도 포스팅을 많이 하기도 했고, plugin을 사용해보고 싶어서 두 번째 방법으로 해보았습니다(vue-cli 버전이 3.x.x에서 작동합니다. vue --version으로 확인하세요).
개발을 하면서 코드 변경이 있으면 자동으로 서버를 재시작해주는 명령어입니다. 이거 없으면 기분이 안 좋아요. 꼭 하세요.
3. frontend, backend 실행
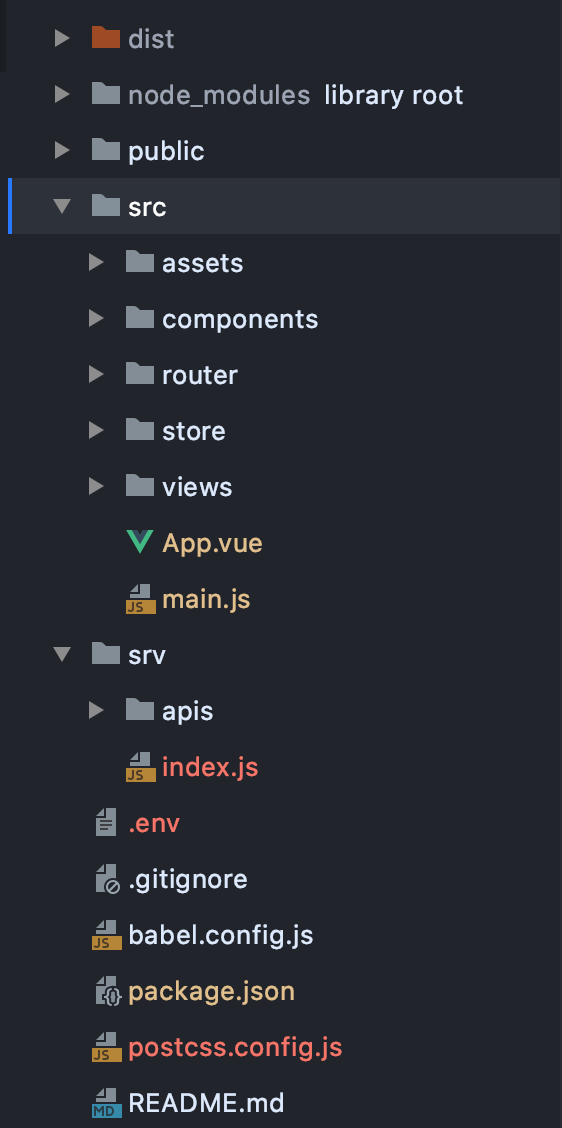
폴더 구조는 다음과 같아지는데 src가 frontend, srv가 backend 폴더라고 보면 쉽습니다.
그럼 실행!
// frontend start - http://localhost:8080
npm run serve
// backend start - http://localhost:3000
npm run express:watch
이렇게 하면 시작할 수 있는데 저 같은 경우에는 port가 frontend는 8080, backend는 3000입니다. 개발환경에 따라 port는 달라질 수 있으니 확인하세요!
4. 라이브러리 설치
이제 웹 크롤링에 사용할 cheerio 라이브러리를 설치!
npm install cheerio
Q. cheerio 말고 다른 라이브러리는 없나요?
A. 기본적으로 웹을 크롤링할 때는 목적이 있습니다. 저처럼 로그인이 필요 없고, 그냥 웹페이지의 내용만 가져올 때는 cheerio가 적합하죠. 가볍고 빠릅니다.
하지만 웹에 들어가서 자동으로 로그인을 한다던가, 클릭해서 팝업창을 열어서 그 내용을 가져온다던가, 드래그 앤 드롭을 한다던가 하는 "javascript의 일"을 해줄 순 없습니다. 그래서 이런 "javascript의 일"을 하기 위해서 selenium, phantomJS, nightmareJS 등 다른 라이브러리를 이용하기도 하니까 목적이 다르다면 위 라이브러리를 검색해보세요.
5. 코드
srv/index.js
import express from 'express'
import cors from 'cors'
import { checkProducts } from "./apis/checkProducts"
export default (app, http) => {
app.use(express.json())
app.use(cors({
origin: 'http://localhost:8080',
credentials: true,
}))
app.post('/check', (req, res) => {
let id = req.body.id
let link = req.body.link
checkProducts(id, link).then( product => {
res.json(product)
}).catch( err => console.log(err) )
})
}
cors는 frontend에서 api 호출할 때 오류가 나서 추가했어요. 오류가 안 난다면 그냥 진행하셔도 무방합니다.
srv/apis/checkProducts.js
import axios from 'axios'
import cheerio from 'cheerio'
function checkProducts(id, url) {
return axios.get( url ).then( ({data}) => {
let $ = cheerio.load(data)
let $prodName = $("div.prod-buy-header h2").text()
let $salePrice = $("div.prod-sale-price span.total-price").text().replace(/[^0-9]/g,'')
let $outOfStock = $('div.oos-label').text().trim()
return {
id: id,
title: $prodName,
salePrice: $salePrice,
outOfStock: $outOfStock
}
})
}
export { checkProducts }
코드는 모두 srv/index.js에 몰아넣어도 되는데, 한 파일에 코드량이 많아지면 읽기가 불편하더라구요, 그래서 그냥 파일을 나눈 것뿐입니다.
진행은 간단합니다.
1. "http://localhost:3000/check"라는 URL로 POST방식을 사용해서 id와 link 파라미터를 전달한다.
2. 전달된 link(url)에 있는 내용을 읽어와서 cheerio를 이용해 원하는 내용만 읽어낸다.
3. 읽어낸 내용을 return 한다(여기서는 frontend로 데이터를 보내준다).
cheerio 라이브러리는 jQuery를 써본 분들은 DOM에 접근하는 방식이 같아서 무난하게 사용할 수 있습니다. 그래도 처음 접하는 분들을 위해 설명을 붙여보자면
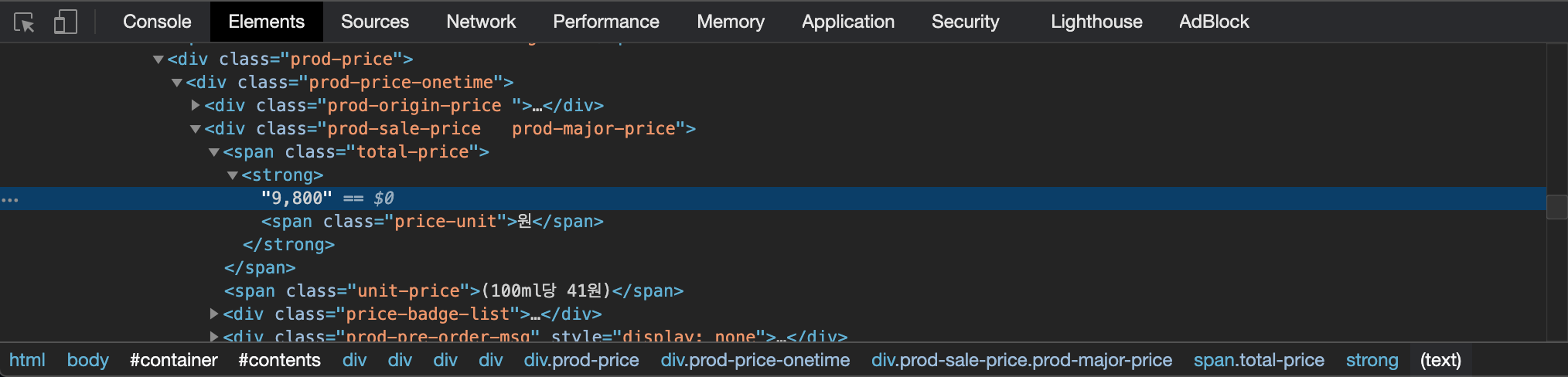
제가 목이 말라서 방금 쿠팡에서 "물"을 검색해서 상품을 하나 골랐습니다. 이 상품의 가격에 접근하는 방법은 크롬 개발자 도구를 이용하면 더 쉽습니다. Elements 탭 가장 하단을 보시면 자기가 클릭한 내용이 어떤 트리로 구성되어있는지 쉽게 보여줍니다.
srv/apis/checkProducts.js
let $salePrice = $("div.prod-sale-price span.total-price").text().replace(/[^0-9]/g,'')
이 부분만 떼어서 보겠습니다. 이 물의 가격에 접근할 때 span.total-price를 통해 접근 가능한데, 혹시 다른 곳에서 같은 태그와 클래스(span태그와 total-price클래스)를 사용할지도 모르니 더 정확하게 상위 태그와 클래스(div.prod-sale-price)를 추가했습니다.
선택된 내용에서 텍스트만 추출(text())해서 따옴표("), 쉼표(,) 같은 녀석들은 정규표현식(replace(/[^0-9]/g,''))을 이용해서 걸러내 줍니다(정규표현식은 구글에서 검색하면 고수들이 알려주니 여기서는 외우거나 이해할 필요는 없습니다. 저도 몰라요).
자 이렇게 구현은 끝났습니다. 정말이지 nodeJS는 정말 강력한 것 같습니다. 제가 들이는 업무의 시간이 1/10로 줄어들었거든요. 앞으로 확인해야 할 상품이 늘어날 걸 예상한다면 시간을 더 아끼는 셈이 되겠네요.