앵간하면 다 가능
링크
① 웹 크롤링 해보기 #1 - NodeJS, cheerio (feat. VueJS)
② 웹 크롤링 해보기 #2 - NodeJS, puppeteer
이번 포스팅에는 저번에 이어서 한번 더 크롤링(crawling or scrapping)을 해볼까 합니다.
이번 포스팅에서는 cheerio라는 라이브러리를 다뤘었는데요. 이번에는 웹에 들어가서 여러 가지 "javascript의 일"을 할 수 있는 라이브러리를 다뤄보려고 합니다. 바로 "꼭두각시"라는 뜻을 가지고 있는 듯한 "Poppeteer"입니다.
cheerio와 다른 점이라면 웹사이트에 로그인을 한다던가, 웹사이트 스크린샷을 찍어서 파일로 저장한다던가, PDF로 만들어서 저장한다던가 하는 일들을 할 수 있습니다.
이번에 제가 보여드릴 예제는 "상품 긁어오기"입니다. 상품을 긁어오는데 cheerio면 충분할 줄 알았는데 복병이 있었습니다. 바로 네이버..
네이버는 상품의 옵션을 보여줄 때 옵션 버튼을 클릭하기 전까지는 옵션의 엘리먼트들을 "hidden"처리를 해놓기 때문에 cheerio로는 긁어오는 것이 불가능합니다.
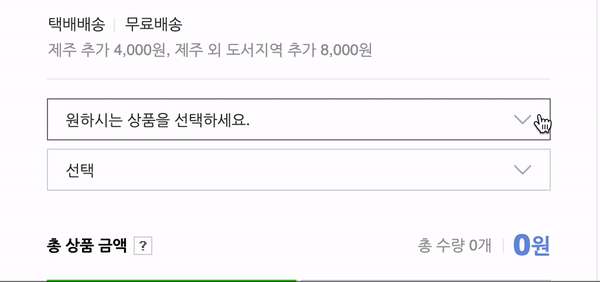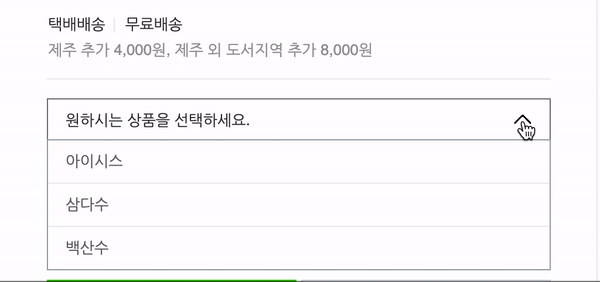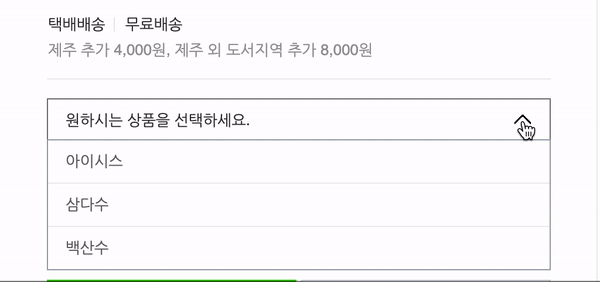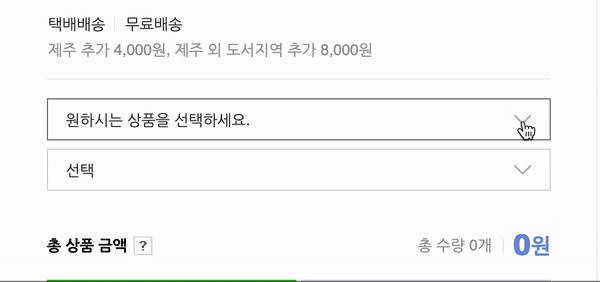
요로코롬 눌러줘야 옵션 창이 뜹니다. 그래서 제가 이야기했던 "자바스크립트의 일"인 버튼을 클릭하는 일을 할 수 있는 라이브러리를 찾던 중에 Puppteer를 발견한 것이었습니다.
이 라이브러리는 chromium의 렌더링 엔진을 사용해서 headless browser 제어를 도와줍니다.
말이 어렵군요.. 제가 이해하는 방식으로 설명해보겠습니다.(저처럼 이해해도 사용하는데 문제가 "아직은" 없었으니까요.)
일반적으로 우리가 사용하는 크롬처럼 GUI방식의 웹브라우저를 CLI(Command Line Interface) 방식으로 제어한다고 생각하면 쉬울 것 같습니다. 맥이면 터미널, 윈도우면 cmd창으로 브라우저를 제어한다는 의미입니다. 크롬 창을 띄우지 않았는데 크롬창을 띄운 것처럼 실행하고 반응하고 원하는 작업을 할 수 있는 것입니다.
자, 그럼 대충 바로 시작해볼게요.
1. 설치를 해야겠죠?
// npm
npm install puppeteer
//yarn
yarn add puppeteer
2. 그리고 nodeJS 파일에 임포트
import puppeteer from 'puppeteer'
3. 그리고 비동기 함수를 만들어 주기
async function scrapeWeb {
// headless browser start
const browser = await puppeteer.launch()
// open new page
const page = await browser.newPage()
// connect web link
await page.goto('http://example.com')
// wait page
await page.waitForNavigation({timeout: 10000})
// click event
await page.click("a.a_class")
// wait option popup
await page.waitForSelector('ul.li_class', {timeout: 10000})
// scrape web data
data = await page.evaluate( () => {
// do something you want
title = document.querySelector("._3oDjSvLwq9").textContent
return {
title: title
}
})
// close browser
await browser.close()
}poppeteer.launch()는 기본값으로 headless로 실행이 됩니다.
page.waitForNavigation({timeout:10000})은 페이지가 완전히 로딩되기를 기다립니다. 이 메소드의 실행 완료를 기다리지 않고 클릭 메소드를 실행해도 ul 엘리먼트가 감지 되지 않아서 꼭 필요합니다. timeout은 기본값이 30초인데, 페이지의 완전한 로딩을 30초 동안 기다려준다는 뜻입니다. 제가 성격이 느긋하다지만 오류가 생겨도 30초는 못기다리겠더라구요. 오류가 생겼으면 빨리 뱉으라는 심정으로 10초로 줄였습니다.(열리더라도 10초 넘게 기다려야되면 그것도 오류아닌가요 여러분?)
페이지의 로딩을 기다리고 클릭도 하고 ul 엘리먼트가 생기는 것을 확인한 후에 page.evaluate() 메소드를 이용해서 하고 싶은 작업을 맘껏 하시면 됩니다.
그리고 잊지 말고 browser.close() 하면 끝.
4. 끝
끝입니다.
5. 번외 & 팁
5-1. page.evaluate에 argument(인자)를 전달하고 싶을 때
page.evaluate( (name) => {
const data = `${name}`
return data
}, name)
5-2. page.evauluate에 인자를 여러 개 전달하고 싶을 때
5-2-1. 객체 법
page.evaluate( ({name, age, gender}) => {
const data = `${name}${age}${gender}`
return data
}, {name, age, gender})5-2-1. 직렬 법
page.evaluate( (name, age, gender) => {
const data = `${name}${age}${gender}`
return data
}, name, age, gender)원하시는 방법대로 인자를 전달하세요.
5-3. page.evaluate() 안에서 console.log는 에러를 뱉어냅니다.
console.log를 하면 에러( Evaluation failed: ReferenceError: _ac2 is not defined )를 뱉어냅니다. _ac2는 랜덤하게 바뀌는 문자열입니다. 정확한 원인을 찾지 못해서, 또는 찾은걸 해봤는데 안 돼서, 또는 찾았는데 이해가 안돼서 그냥 저는 값을 계속 return 시켜보면서 확인했습니다.
=>2021.3.13 추가
역시 모르면 공부하면 알게되는데 귀찮아서 미루고 있다가 지금 알게되었습니다. evaluate는 저쪽 크롤링을 시전하고 있는 puppeteer쪽 크롬창에 명령을 한번에 전달하는 메소드입니다. 그래서 그 안에 console.log를 하면 저쪽 크롬창에 뜨게 되는 것이죠. puppeteer를 launch할 때 옵션으로 {headless: false}옵션을 주면 창이 하나 뜨면서 확인이 가능합니다. 물론 나중에는 다시 꺼놔야겠지요!
링크
① 웹 크롤링 해보기 #1 - NodeJS, cheerio (feat. VueJS)
② 웹 크롤링 해보기 #2 - NodeJS, puppeteer
5-3 해결 방법 아시는 분? 해답이 이제는 필요 없지만 찍히는 거 보고 싶어요.
'기록일지 > NodeJS' 카테고리의 다른 글
| Crypto를 이용한 Hash, HMAC 생성하기(feat. 쇼핑몰 API) (0) | 2020.10.15 |
|---|---|
| 웹 크롤링 해보기 #1 - NodeJS, cheerio (feat. VueJS) (0) | 2020.09.30 |